| tensorflow模型保存及调用 | 您所在的位置:网站首页 › tensorflow 加载模型进行预测 › tensorflow模型保存及调用 |
tensorflow模型保存及调用
|
tensorflow2.0模型保存有以下几种方式: 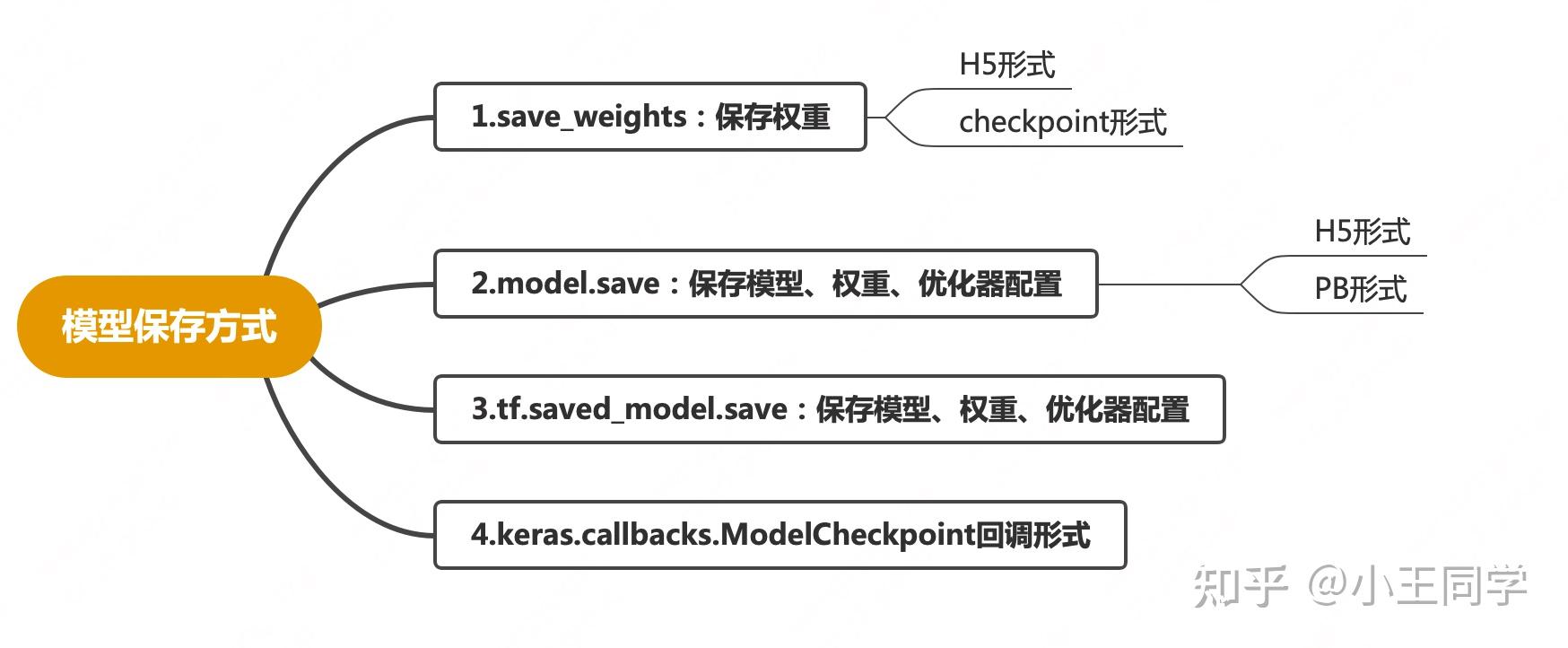 tensorflow模型保存方式一、创建模型import numpy as np
import tensorflow as tf
# 训练数据
x_train = np.random.random((1000, 32))
y_train = np.random.randint(10, size=(1000, ))
# 验证数据
x_val = np.random.random((200, 32))
y_val = np.random.randint(10, size=(200, ))
# 测试数据
x_test = np.random.random((200, 32))
y_test = np.random.randint(10, size=(200, ))
# 构造模型
def get_uncompiled_model():
inputs = tf.keras.Input(shape=(32,), name='digits')
x = tf.keras.layers.Dense(64, activation='relu', name='dense_1')(inputs)
x = tf.keras.layers.Dense(64, activation='relu', name='dense_2')(x)
outputs = tf.keras.layers.Dense(10, name='predictions')(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
return model
# 设置优化器和损失函数
def get_compiled_model():
model = get_uncompiled_model()
model.compile(optimizer=tf.keras.optimizers.RMSprop(learning_rate=1e-3),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['sparse_categorical_accuracy'])
return model
model = get_compiled_model()
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_val, y_val))二、保存及调用2.1 方式一:保存权重 tensorflow模型保存方式一、创建模型import numpy as np
import tensorflow as tf
# 训练数据
x_train = np.random.random((1000, 32))
y_train = np.random.randint(10, size=(1000, ))
# 验证数据
x_val = np.random.random((200, 32))
y_val = np.random.randint(10, size=(200, ))
# 测试数据
x_test = np.random.random((200, 32))
y_test = np.random.randint(10, size=(200, ))
# 构造模型
def get_uncompiled_model():
inputs = tf.keras.Input(shape=(32,), name='digits')
x = tf.keras.layers.Dense(64, activation='relu', name='dense_1')(inputs)
x = tf.keras.layers.Dense(64, activation='relu', name='dense_2')(x)
outputs = tf.keras.layers.Dense(10, name='predictions')(x)
model = tf.keras.Model(inputs=inputs, outputs=outputs)
return model
# 设置优化器和损失函数
def get_compiled_model():
model = get_uncompiled_model()
model.compile(optimizer=tf.keras.optimizers.RMSprop(learning_rate=1e-3),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['sparse_categorical_accuracy'])
return model
model = get_compiled_model()
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_val, y_val))二、保存及调用2.1 方式一:保存权重特点:仅保存模型参数,没保存模型结构,因此模型文件小,且加载时需要再次描述模型结构 (1)H5形式 model.save_weights("adasd.h5") model.load_weights("adasd.h5") model.predict(x_test) H5文件 H5文件(2)checkpoint形式 model.save_weights('./checkpoints/mannul_checkpoint') model.load_weights('./checkpoints/mannul_checkpoint') model.predict(x_test) checkpoint文件2.2 方式二:保存模型+权重-model.save checkpoint文件2.2 方式二:保存模型+权重-model.save特点:保存模型及参数,加载时不需要再次描述模型结构 (1)pb形式 # Export the model to a SavedModel model.save('keras_model_tf_version', save_format='tf') # Recreate the exact same model new_model = tf.keras.models.load_model('keras_model_tf_version') new_model.predict(x_test) 模型文件夹 模型文件夹 模型文件内部 模型文件内部(2)H5形式 model.save('keras_model_hdf5_version.h5') new_model = tf.keras.models.load_model('keras_model_hdf5_version.h5') new_model.predict(x_test) 模型文件2.3 方式三:保存模型+权重-tf.saved_model 模型文件2.3 方式三:保存模型+权重-tf.saved_model特点:tf.saved_model.load加载的模型不是keras的模型,所以不能用model.predict()对测试数据进行预测。 tf.saved_model.save(model,'tf_saved_model_version') # 模型保存 restored_saved_model = tf.saved_model.load('tf_saved_model_version') # 模型加载 f = restored_saved_model.signatures["serving_default"] f(digits = tf.constant(x_test.tolist())) # 模型预测 模型文件夹 模型文件夹 模型文件内部2.4 方式四:checkpoint回调形式保存模型 模型文件内部2.4 方式四:checkpoint回调形式保存模型checkpoint回调形式一般和EarlyStopping回调函数结合使用 (1)EarlyStopping EarlyStopping:经过了数轮后,目标指标不再有改善了,就可以提前终止,节省时间 keras.callbacks.EarlyStopping( monitor='val_loss', min_delta=0, patience=0, verbose=0, mode='auto', baseline=None, restore_best_weights=False )monitor: 监测指标min_delta: 在被监测的数据中被认为是提升的最小变化, 例如,小于 min_delta 的绝对变化会被认为没有提升。patience: 没有进步的训练轮数,在这之后训练就会被停止。verbose: 详细信息模式。mode: {auto, min, max} 其中之一。 在 min 模式中,当被监测的数据停止下降,训练就会停止;在 max 模式中,当被监测的数据停止上升,训练就会停止;在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。baseline: 要监控的数量的基准值。 如果模型没有显示基准的改善,训练将停止。restore_best_weights: 是否从具有监测数量的最佳值的时期恢复模型权重。 如果为 False,则使用在训练的最后一步获得的模型权重。(2)checkpoint 模型中断时,可以结合ModelCheckpoint来保存模型,这样我们可以保证只保存的是最佳模型。 keras.callbacks.ModelCheckpoint( filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1 )filepath: 字符串,保存模型的路径monitor: 被监测的数据verbose: 详细信息模式,0 或者 1 save_best_only: 如果 save_best_only=True, 被监测数据的最佳模型就不会被覆盖mode: {auto, min, max} 的其中之一。 如果 save_best_only=True,那么是否覆盖保存文件的决定就取决于被监测数据的最大或者最小值。 对于 val_acc,模式就会是 max,而对于 val_loss,模式就需要是 min,等等。 在 auto 模式中,方向会自动从被监测的数据的名字中判断出来save_weights_only: 如果 True,那么只有模型的权重会被保存 (model.save_weights(filepath)), 否则的话,整个模型会被保存 (model.save(filepath))period: 每个检查点之间的间隔(训练轮数)import keras callbacks_list = [ # 目标指标不再有改善了,就可以提前终止 keras.callbacks.EarlyStopping( monitor='acc', # 被监测的模型的精度 patience=1 # 没有进步的训练轮数为1,在这之后训练就会被停止 ), # 保存模型 keras.callbacks.ModelCheckpoint( filepath = 'my_model.h5', # 文件路径 monitor='val_loss', # 如果val_loss 没有改善就不覆盖 save_best_only=True, # 保持最佳模型 save_weights_only=False) #保存模型+权重 ] model.fit(x,y, epochs=10, batch_size=32, callbacks=callbacks_list, validation_data=(x_val,y_val))三、参考文章TensorFlow2.0 -- 模型保存与加载 fit函数 model_深度学习笔记38_利用回调函数保存最佳的模型 |
【本文地址】
公司简介
联系我们
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |